
概述
支持的模型
qwen-max、 qwen-plus 、qwen-turbo模型。功能介绍
如何使用
我们会定期清理一段时间内没有使用的缓存信息。
如何计费
cached_token 来计费,cached_token的单价为input_token单价的40%;未被命中的 Token 仍按照 input_token计费。假设某一次请求的输入 Token 数为10,000,有5,000个 Token 被系统判断命中了 Cache,则 input_token 的计费为未开启 Context Cache 模式的 70%[(50% 未命中 Cache Token)*100%单价 + (50% 命中 Cache Token)*40%单价] )。计费示意图如下:output_token仍按原价计费。
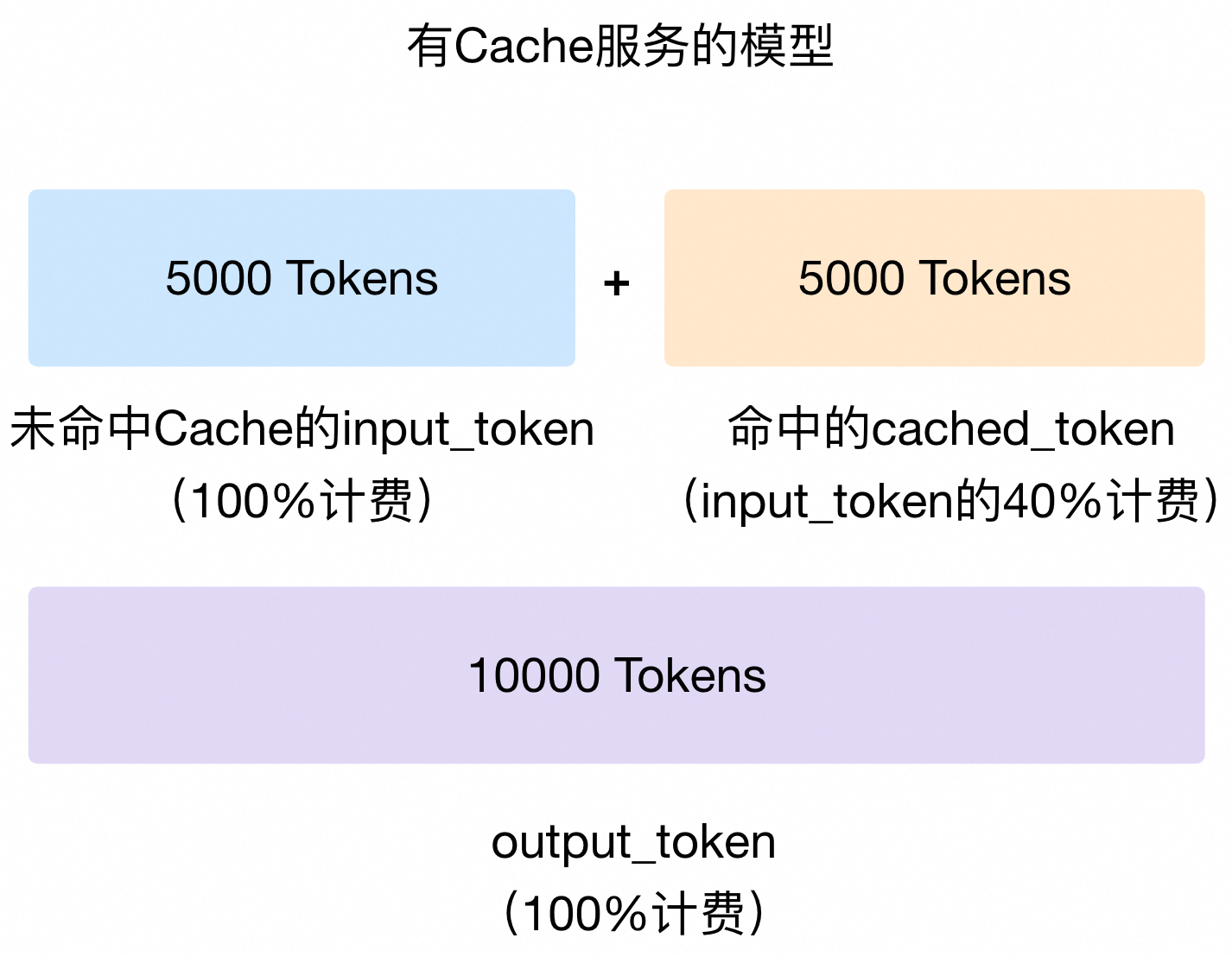
cached_tokens属性获取命中 Cache 的 Token 数。如果您通过Batch方式调用,则无法享受 Cache 的折扣。
如何提升命中 Cache 的概率
在您使用该功能时,不足 256 Token 的内容不会被缓存。
工作方式
1.
2.
1.
2.
命中 Cache 的案例
OpenAI兼容
usage.prompt_tokens_details.cached_tokens可以查看命中 Cache 的 Token 数(该 Token 数包含在usage.prompt_tokens中)。{
"choices": [
{
"message": {
"role": "assistant",
"content": "我是阿里云开发的一款超大规模语言模型,我叫通义千问。"
},
"finish_reason": "stop",
"index": 0,
"logprobs": null
}
],
"object": "chat.completion",
"usage": {
"prompt_tokens": 3019,
"completion_tokens": 104,
"total_tokens": 3123,
"prompt_tokens_details": {
"cached_tokens": 2048
}
},
"created": 1735120033,
"system_fingerprint": null,
"model": "qwen-plus",
"id": "chatcmpl-6ada9ed2-7f33-9de2-8bb0-78bd4035025a"
}典型场景
1.
2.
3.
4.


 扫码关注公众号
扫码关注公众号修改于 2025-09-16 14:10:46